
Object-Oriented Brain Rot
Is a square a subclass of rectangle or a rectangle a subclass of square?

Despite my “pen name” clearly pointing out my propensity to complain, it’s not actually something I particularly enjoy doing. I do it because I care. I’d much rather teach cool stuff, but sometimes I get so annoyed at something that I need to vent and this is one of those blog posts.
Disclaimer 1: Opinions expressed here are solely my own and do not express the views or opinions of my employer.
As part of my job I’ve been developing an implementation of the Systems Modeling Language 2.0 standard (typically referred to as SysMLv2). Think UML but for Systems Engineering (aerospace, automotive, etc.) and designed by the same people, OMG.
Content-wise I think it’s a pretty good standard. It has all the stuff I’d expect to find1 and while the way you specify some things is a little weird, it could be much worse. It’s certainly better than UML or its previous iteration (SysMLv1).
Specification-wise, however, it is abysmal. Implementing this thing is an exercise in frustration. There’s a whole separate spec (KerML) that has to be understood and implemented first even though maybe 3 people max actually care about the distinction. Every concept is specified as a UML class, some with 10+ levels of inheritance, including multiple-inheritance.
The associations between concepts are all bidirectional and are overridden multiple times throughout the inheritance chain, e.g., one class might have an association with a multiplicity of 0..*, unique, unordered; a subclass redefines it to have multiplicity 0..1; a subclass of that subclass redefines it again to be multiplicity 1..*, non-unique, ordered. Barbara Liskov and her substitution principle be damned.
But relationships in SysMLv2 are reified as their own objects, so what you technically have are bidirectional associations (in a UML sense) between SysMLv2 elements and SysMLv2 relationships (which are also SysMLv2 elements), and then between the relationships and other elements. You can’t just get the “value” of an AttributeUsage, there’s a thing in the KerML standard library that attributes must specialize which is how you’re supposed to access their values, and in order to actually find the data you have to dig through multiple levels of relationships to find a FeatureValue2 which is the relationship that has an association with the damn value.
It’s everything wrong with object oriented design dialed up to 11 until the knob breaks. I despise it. But this post isn’t actually about SysMLv2. The SysMLv2 specification is a manifestation of a much bigger issue: Object-Oriented Brain-Rot3.
I find that doing too much OOP leads to the degradation of mental faculties, intelligence, and common sense. Hence the term brain-rot.
Disclaimer 2: I have nothing against objects and interfaces, I think they’re nearly fundamental computational constructs. Even a closure can be seen as an object whose interface is a single method. This post is about a type of thinking.
Is a Square a Rectangle?
In geometry a square is a kind of rectangle. All squares are rectangles, but not all rectangles are squares. In OOP, things are a little trickier. Consider:
class Rectangle : Shape {
double width;
double height;
Rectangle(double width, double height) {
this.width = width; this.height = height;
}
double getArea() {
return width * height;
}
}
class Square : Rectangle {
Square(double length) {
this.width = length;
this.height = length;
}
double getArea() {
return width * width;
}
}The above code has a major issue:
Rectangle r = Square(10);
r.height = 20;
print(r.getArea()); // oopsSquare breaks the Liskov Substitution Principle. I can do things with a Rectangle (like setting its height separately from its width) which I cannot do with a Square. The typical solutions are to make the objects immutable, or to make both inherit from Shape directly.
But why do Rectangle and Square need to be modeled as objects in the first place? What’s their behavior? What is the “Single Responsibility” of a Rectangle or a Square?
While the exercise is meant as a way to showcase potential issues arising from modeling real world taxonomies as object-oriented class hierarchies4, to me the very existence of the exercise is problematic, because it means people are trying to model things as class hierarchies that shouldn’t be class hierarchies in the first place.
What problem are you solving?
The issue starts with the very act of modeling Rectangles and Squares as a class hierarchy. Why are you doing this? What purpose do these classes serve? You’re building some sort of application, what is the purpose of Square in the application?
Consider as an example a video game. For whatever reason I may need to draw a square onscreen. Do I need an actual Square object that subclasses Shape with a draw method or so? No.
The square emerges from some game state that requires the appearance of a square onscreen. There’s no need to store the square itself at any point, it is derived from other data. A “square” can be something as simple as:
void draw_square(int x, int y, int length) {
draw_rectangle(x, y, length, length);
}While a “rectangle” might be:
void draw_rectangle(int x, int y, double width, double height) {
Point points[] = {
{x, y}, {x+width, y},
{x+width, y+height}, {x, y+height}
};
draw_polygon(points);
}The screen gets redrawn every frame so keeping the data for the shapes around is completely unnecessary. Maybe you’re drawing a square because a unit has been selected in a strategy game and the square serves as the selection border. The square exists while the unit is selected, and does not exist otherwise.
But maybe you’re not actually working on a game. Perhaps you’re working on a vector drawing application where the user can add squares and rectangles and edit them. In this case you actually need to store squares and rectangles as actual entities.
But even then, do squares and rectangles need to be modeled as separate classes? A square is usually just a rectangle whose width and height are the same. In almost every vector drawing app you only have “rectangles”, even if you create a “square” you’re given the option of setting the width and height separately because that is what is most useful in a drawing application.
What about rounded rectangles? Is “RoundedRectangle” a subclass of Rectangle? Just have rounded corners be a property of rectangles. I have separate buttons to add rectangles and rounded rectangles in Pixelmator Pro but all they do is set a different default for the rounding of the corners, the entity produced is the same. There’s no need to model a separate concept. All a “rectangle” really is in such an app, ultimately, is a convenient user interface to manipulate some Bézier curves.
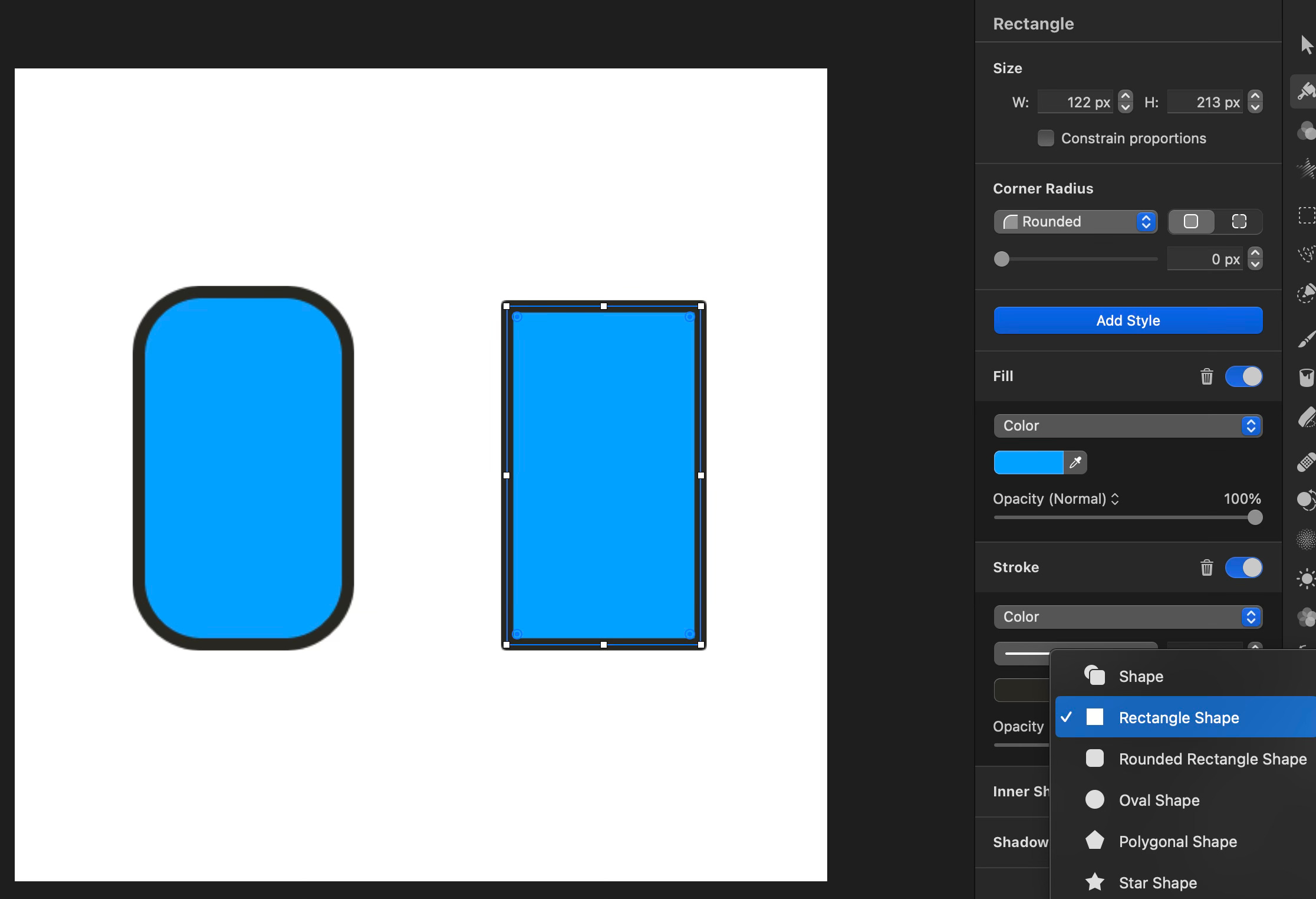
There’s no need to waste time worrying about how well whatever concepts fit into your class hierarchy. You don’t need the class hierarchy and you need the real-world relations between the concepts even less. Just write the code that solves the problem.
What if the relations are the point?
In SysMLv2 the relations between the various concepts are relevant. The taxonomy itself is important information. But imposing that structure onto a codebase is a very strange thing to do. Why does the code need to reflect the taxonomy? If you care about relations, just model them directly. Here’s how you model the relation between a square and a rectangle in Datalog or Answer set programming:
% every square is a rectangle with the same width and height
rectangle(Id, L, L) :- square(Id, L).
% every rectangle of equal width and height is a square
square(Id, L) :- rectangle(Id, L, L).With the above rules, I can add some facts to the database and have the set of squares and rectangles be kept consistent and up-to-date automatically:
square(a, 3).
square(b, 5).
rectangle(c, 1, 2).
rectangle(d, 4, 4).
rectangle(c, 8, 7).If I query all the squares, then I get a, b and d. Even though I defined d as a rectangle, it is automatically defined as a square as well. Similarly if I query all the rectangles, I get all 5 entities. That’s how you model bidirectional relationships. Trivial.
By using the right tool for the job I made my life a lot easier. Had I suffered from OO brain-rot like OMG seems to, I would have made a class hierarchy. But then I could make a rectangle with equal width and height that for whatever reason is not a square.
It is entirely the wrong tool for the job. You’ve applied object-oriented design so much that you see it as not only the solution to everything, but a necessary first step.
Your mental faculties have actually decreased as a result. As a newbie you would just solve the problem directly, you wouldn’t even waste time on this, and the outcome would be better. What else can this be called besides brain-rot?
A paradigm made of straw
Some readers may accuse me of making up a straw man and that this has nothing to do with OOP, but I disagree. The two are very much intertwined. While you can certainly use objects and interfaces in reasonable ways, that’s not how OOP is taught and practiced. When I was in university and learning OOP, object-oriented design was always at the forefront.
From the very beginning we were learning how Cat and Dog are subclasses of Mammal which in turn is a subclass of Animal. Though maybe they should be subclasses of Feline and Canine respectively? What about Carnivore? Do we use multiple-inheritance?
While the exercise was meant to explain inheritance, I really need to stress out how it was entirely disconnected from solving an actual problem. The same pattern repeated later when we were modeling “Customers” and “Employees” as subclasses of “Person”. Once again, a taxonomy that did not serve any actual purpose in solving a problem. All a customer really was in the end was an ID in a database.
This is what students are being evaluated on, and it’s how they learn to think about problems: in terms of object-oriented design. That the first step to creating a software solution is to model a taxonomy of concepts as a class hierarchy. This is a detrimental and unproductive way of thinking. It creates a rigid structure in the codebase that does not reflect the actual needs of the codebase, making it a pain to work with.
As an example, consider how people turn their noses at “Utils” or “Manager” classes even though just having some extra functions laying around is often the simplest and most natural approach. What issues are such classes actually causing, beyond going against some nonsensical object-oriented design ideal5?
Later those same students go to a job interview and are questioned on their knowledge of design patterns, another entirely wrong way to look at problems. You don’t need the Visitor Pattern, you need sum types (even C can do them).
So a combo-wombo of an entirely wrong way to think about problems, leading to poor program structure, plus rote memorization of patterns meant to solve the structural issues caused by the paradigm.
If you’re worried about maintainability, which is what OOP is supposedly good at6, then making a class-hierarchy based on a real-world taxonomy is the worst thing you can possibly do. Even serious real-world taxonomies need to be changed from time to time. Your partial taxonomy is going to have to change and the rigid structure it imposed on your codebase won’t make it easy.
Reset your brain and focus on the problem. You have data that needs to be transformed and/or moved around. How to accomplish that in a simple and performant manner? That’s all you need to care about.
Though it is, notably, missing positioning information for the visual representation. I find this utterly bizarre as it was a major complaint of the first version. Guess they were too busy making the spec as convoluted as they could get away with to worry about such minutiae.
Truly it is a Kingdom of Nouns.
There are many other forms of brain-rot in software engineering, including functional brain-rot where every function needs to be as generic as possible using monad transformers or what have you, even though all you’re doing is parsing a JSON file. That’s just as bad.
Which, as the rest of the article hopefully shows, is a good thing for an exercise to teach. But it’s focusing on the wrong thing. The issue is not the perils of modeling real-world concepts as a class hierarchy, it’s that real-world concepts should never be modeled as a class hierarchy. There’s no reason to.
Well, the classes shouldn’t exist in the first place, they’re just a pile of functions. It’s the language that’s imposing they be stored inside a class. More OOP brain-rot, only in this case on the part of the language designer.
It really isn’t IMO. It’s a great way to implement extensible plugin systems, which may sound like it makes the system easy to maintain (if it’s easy to extend then it must be easy to maintain right?), but plugin systems require a rigid interface. Rigid. As in, hard to change.
I should write an article on this someday but I think it's important to emphasize that objects in programming are very much about providing features for programming and shouldn't be thought of as something to model real world phenomena. Whether something inherits from a base class should depend on whether you're trying to reuse or extend previously written code and it makes sense to do so. But even that's an oversimplification because the decision on whether to reuse code and how difficult in general.
Part of the issue is that inheritance functions like a "module system", and most object oriented languages have module systems that aren't object oriented (C++ has header files, in addition to OOP inheritance) and the differences between these two systems add up to complicated tradeoffs. Sometimes it's obvious which one to use and sometimes it isn't.
Square and rectangles, even the taxonomy example, while compelling in your writing, could be defended as great use cases for OOP — the article merely expose naïve implementation, not misapplication
Let's illustrate with moderate depth the taxonomy of life, a great use case for OOP.
Hierarchy
Life
├── Plantae
└── Animal
└── Mammal
├── Dog
├── Cat
└── Dolphin
- Core traits (e.g., warm-bloodedness) propagate upward via inheritance
- Shared behaviors (e.g mammal.eat()) are defined at highest applicable level
- Behaviors can be override
These are basically what inheritance gives us. But inheritance != OOP (that's more than that)
So how to deal with Cross-Cutting Concerns (e.g Carnivore, Aquatic, younameit)?
**Composition**
-> Attach traits like Carnivore or Aquatic as components (or properties, if you like, properties can be classes.
Or
**Interfaces**
-> I favour composing, but interfaces can be implemented by classes. Or the interfaces provides the implementation.
See the Serializable interface in Java, for a beautiful abdtraction that saved the need for millions of developers to have a single clue how that works, yet their stated does serialize just fine.
Back to our taxonomy of life:
A Diet component could drive hunt() logic, with context (e.g., "walk" vs. "dive") determined by other traits.
Interfaces: Use ICarnivore or IAquatic to enforce capabilities without inheritance. A dolphin implements both, inheriting swim() from IAquatic and overriding hunt() via Diet.
Flexibility Without Chaos
Common DNA/gene logic lives in Life, inherited by all.
Niche behaviors (e.g., hunting style) are encapsulated in composable modules, avoiding brittle hierarchies.
I would suggested exploring how OOP can address all the concerns your article discussed. It's not to say OOP is a magic bullet everyone should force into everything, I agree with many times it is forced in, induces complexity, bugs for no benefits. But the examples you used could well be turned around with "design patterns", but also good judgement.